

Simennzz
-
Innlegg
161 -
Ble med
-
Besøkte siden sist
Innholdstype
Profiler
Forum
Hendelser
Blogger
Om forumet
Innlegg skrevet av Simennzz
-
-
Jeg fikk noe annerledes på oppgave H, bortsett fra det er alt likt!
Ser at du har med vce(robust), hvordan er det man får til det på stata?
Denne er også korrekt (Innlegget til Anonym1 med wordfil). vce(robust) skal ikke være med i utregningen av Oppgave H.
Det er forsåvidt ingenting som tilsier at du trenger kjøre level(99) for å få et 99% konfidensintervall. Det i forhold til hvilket signifikansnivå du skal teste mot oppgave E. Men om du tar med et 95% konfidensintervall eller 99% tviler jeg har noe å si, da vi ikke pleier å få spørsmål rundt de tallene i stata.
-
Ser forsåvidt at alle oppgavene i Nimrad sin pdf fil er korrekte, så fremt min kunnskap holder mål.
-
Hei! Jeg har en oppgave fra høst 2011, som lyder som følger: Anta at antall observasjoner som brukes i estimeringen av modellene i forrige oppgave er lik 34. Hva er kritisk verdi til testen hvis et 5% signifikansnivå brukes?
Her trodde jeg at jeg gikk inn i kritiske verdier for 5% og gikk ned til 30? (Antall b'er er 4). Men jeg finner jo ikke svaret som er 3,32 i tabellen... Har slitt på lignende oppgaver også

Du tester to restriksjoner, mens det er 4 regresjonskoeffesienter og 34 utvalgte.
m = 2, n = 34, k = 4
Da må du sjekke F df1, df2, der df1 = m og df2 = (n-k)
Altså F2,30, ser i tabellen F (df1, df1) fordeling på 5% signifikansnivå, og finner 3,316 som gjøres om til 3,32.
Har lurt på det samme, hvordan vet man når man skal bruke F df1, df2, der df1 = m og df2 = (n-k) istedenfor?
Også, hvorfor gjøres 3.316 om til 3.32 av alle tall?
Forstod ikke helt det første spørsmålet?
3,316 opprundet blir 3,32.
-
På eksamen høst 2011 på oppgave 18, så skal man finne kritisk verdi på 1% signifikansnivå med df=30.
Da ser jeg i tabellen at den kritiske verdien er 2,457, men i fasiten er det -2,457.
Hvorfor blir det minus foran?
Det spørres om når B1 < 0. Altså når B1 er mindre en null, derfor blir det negativt. Hadde det vært B1 > 0 hadde den vært positiv.
-
Hei! Sliter litt med oppg H. Har sammenlignet resultatet jeg fikk med det bildet som ble postet av samme oppg tidligere og ser forskjeller mellom konfidensintervallene våre.
Kan noen se om dette ser feil/riktig ut?
. regress worrylevel areaopinion victim12m female age d2, vce(robust) level(99)
Linear regression Number of obs = 7224
F( 5, 7218) = 331.66
Prob > F = 0.0000
R-squared = 0.1912
Root MSE = .90051
------------------------------------------------------------------------------
| Robust
worrylevel | Coef. Std. Err. t P>|t| [99% Conf. Interval]
-------------+----------------------------------------------------------------
areaopinion | .3096498 .0123795 25.01 0.000 .2777539 .3415457
victim12m | -.0899392 .0273014 -3.29 0.001 -.1602814 -.0195969
female | .6007161 .0210408 28.55 0.000 .5465042 .654928
age | -.0024202 .0006677 -3.62 0.000 -.0041406 -.0006998
d2 | -.1691402 .0214493 -7.89 0.000 -.2244045 -.1138759
_cons | -.0681522 .0393837 -1.73 0.084 -.1696247 .0333204
------------------------------------------------------------------------------
Dette er feil, til info. d2 har ingenting her å gjøre, og du skal ikke regne denne robust, du skal først regne E'en robust (Ikke i Oppgave E, men for å få riktige p-verdier), så lese av hvilke variabler du skal ha, for å gjøre en vanlig regresjon til oppgave H.
D2 har heller ingenting å gjøre der, verken i caset eller oppgaven, da de oppgir spesifikt hva dummyvariablene skal hete.
-
k=4 tenker du kanskje?
Riktig, skriveleif, tok n-k istedenfor.
-
Hei! Jeg har en oppgave fra høst 2011, som lyder som følger: Anta at antall observasjoner som brukes i estimeringen av modellene i forrige oppgave er lik 34. Hva er kritisk verdi til testen hvis et 5% signifikansnivå brukes?
Her trodde jeg at jeg gikk inn i kritiske verdier for 5% og gikk ned til 30? (Antall b'er er 4). Men jeg finner jo ikke svaret som er 3,32 i tabellen... Har slitt på lignende oppgaver også
Du tester to restriksjoner, mens det er 4 regresjonskoeffesienter og 34 utvalgte.
m = 2, n = 34, k = 4
Da må du sjekke F df1, df2, der df1 = m og df2 = (n-k)
Altså F2,30, ser i tabellen F (df1, df1) fordeling på 5% signifikansnivå, og finner 3,316 som gjøres om til 3,32.
-
Noen som kan hjelpe med denne? Høsten 2012. Jeg forstår den ikke helt, det jeg lurer på:
Hvor finner man p-verdien? Hvordan bestemmer man hva som er korrekt eller ikke?
Legger med fasit og
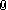 Skjermbilde 2014-05-20 kl. 17.40.45.pngSkjermbilde 2014-05-20 kl. 17.42.19.png
Skjermbilde 2014-05-20 kl. 17.40.45.pngSkjermbilde 2014-05-20 kl. 17.42.19.pngSatt å funderte på den selv, i mine Stata utregninger fikk jeg at p-verdien er 0.000, så oppdaget jeg at i caset i fasiten, så har de fått 0,0082, så jeg kan ikke helt forstå hvorfor det skjer, om det er en Stata feil eller hva det er (Prøvde å kjøre den robust og, samme greia).
Med p verdi 0,0082, eller 0,82%, så tester du alle.
a) Her er B3 positiv (altså større enn null ( B3 > 0 )), så da tester du med p-verdien 0,0082 / 2 = 0,0041, som er 0,41%. Det er lavere enn p-verdien, så den er korrekt.
b) Når B3 ikke er 0, så er p-verdien 0,82%. Det er lavere enn 5%, så den er korrekt.
c) Samme som b, 0,82% er lavere enn 1%, så denne er også korrekt.
d) Her spør de når B3 er negativ (altså mindre enn null ( B3 < 0 )), hvis du husker noe fra statistikk, så må du da 1 minus z-verdien (delt på to siden det er en tosidig alternativhypotese); da får du 1 - (0,0082 / 2) = 0,9959 altså 99,59%. Da ser vi at d) ikke er korrekt, og svaret på oppgaven.
Håper det var til hjelp
-
I en oppgave så er predikert salg = e^4,4863 = 88,7923.
Hvordan trykker man dette på kalkulatoren så man finner dette svaret?
Du skriver inn 4,4863, så "2nd", så "LN" (der står e^x i gult).
Hadde helt glemt av denne tråden.
-
Er så unødvendig å legge ut alle svarene og la folk få pass på arbeidskrav istedenfor at de må jobbe og lære..
-
n-1/n-k-1?
(63-1)/(63-2-1)
Det er (n-1) / (n-k)
-
På oppgave 14 får jeg følgende oppstilling:
=1-(1-0,1156)*(62/60)= 0,0812 men dette stemmer ikke med alternativene, hva er feil med den oppstillingen?
n=63 k=2
Hvor får du 60 ifra, hvis k = 2?
-
Hei, kan du oppgi svarene fra 1-10 og løsningene om det er mulig? Vil sammenlikne svarene XPHar nå fullført arbeidskravet og fikk 20/20, så bare å hyle ut om noen lurer på noe.
Hei!
Du får vite om svaret ditt er rett når du leverer det inn og du har 13 forsøk på arbeidskravet, så det gir ikke helt mening..
Med å hjelpe her oppfordrer jeg til at folk prøver mer selv, ikke for å gi snarveier til folk.
(Sier ikke du er ute etter det, bare hvis jeg legger 10 svar her så kan folk bare skrive det inn og bli ferdig)
-
Strålende, takk!
Oppgave 13 da? Hvor henter jeg tallene fra for fylle inn i formelen?
Du har oppgitt at utvalgskorrelasjonen er 0,34. Du tar den og opphøyer i andre og får at R2 = 0,1156
Lurer litt på oppgave 5..
Har kommet til rett svar ved hjelp av Fobs formelen, men lurer litt på hva dere har gjort i selve programmet? Jeg tok bare RSS og RSSu ved hjelp av å kjøre Linear regression i stata, fikk tallene og regnet svaret ut ved hjelp av kalkulator. Er det slik man skal gjøre det, eller er det en måte i selve programmet å komme fram til svaret, altså 1,42?
Deretter lurer jeg litt på oppgave 6, hvordan kom dere fram til svar der?
Sett at det programmet er veldig avansert, så fins det sikkert en måte. Om det er en måte har vi enda ikke lært den hvertfall.
På oppgave 6 må du bare slå opp i tabellen på F3,23 (F-test på m og n-k) og se om noen av de verdiene er lavere enn F verdien du regnet ut (1,42). Er verdien lavere på en av signifikansnivåene blir h0 forkastet, er alle høyere beholdes h0.
-
Hvordan har du løst oppgave 12 Simennzz?
For å finne b2 kan du bruke b2 = Kov (x,y) / Var(x)
Kovariansen til (x,y) fant du i forrige oppgave og den var 16,98 (sett at du har gjort oppgaven rett)
Variansen til x (i dette tilfellet er x = CAR) er 1,31
16,98 / 1,31 = 12,96x eller 12,96 CAR
Så kan du bruke formelen b1 = y¯ - b2 * x¯
y¯ = gjennomsnitt av Y (I dette tilfellet NO2)
x¯ = gjennomsnitt av X (I dette tilfellet CAR)
Da får du 52,11 - 12,96 * 1,63 = 30,99
-
Har nå fullført arbeidskravet og fikk 20/20, så bare å hyle ut om noen lurer på noe.
-
Og da får du:
(1361,8004 - 1149 ) / 3) / ((1149 / 30 - 7)) = 1,42 -
Men det store spørsmålet. RSSu, vet du hvordan man finner den i Stata? Om jeg kjører en constrained linear regression får jeg ikke opp noe RSS. Men siden disse B-ene skal være null, vil jeg få samme svar om jeg kjører en vanlig linear regression og bare utelater de variablene som skal være null?Om jeg ikke tar helt feil, så tar du først dependent y med alle x'ene, og tar RSSu der ifra.
Etter på tar du dependent y og alle de x'ene som er igjen etter å ha satt B'ene som 0, altså
dependent y og independent x2 x3 og x4
Så tar du RSS'en fra dette datasettet, og får RSSr
m = 3, n = 30 og k = 7
Så kan du bruke :
((RSSr - RSSu) / m) / ((RSSu / (n - k )) = 1,42
Har ikke sjekket om svaret er rett enda, men virker logisk.
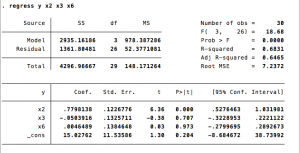
RSSu har du allerede postet bilde av (1149)
RSSr får du ved å utelate de x'ene som blir null ved følge av at hypotesen sier at de B'ene skal være 0. Da skal du få dette:
-
Om jeg ikke tar helt feil, så tar du først dependent y med alle x'ene, og tar RSSu der ifra.
Etter på tar du dependent y og alle de x'ene som er igjen etter å ha satt B'ene som 0, altså
dependent y og independent x2 x3 og x4
Så tar du RSS'en fra dette datasettet, og får RSSr
m = 3, n = 30 og k = 7
Så kan du bruke :
((RSSr - RSSu) / m) / ((RSSu / (n - k )) = 1,42
Har ikke sjekket om svaret er rett enda, men virker logisk.
Skjønner ikke helt hvor man finner RSS'en i datasettet?
Altså skjønner hvordan man ordner dependent og independent, og får frem datasettet. Men hvor ligger RSS'en?
Hvis du ser på modellen til Nimrad oppe til venstre, ser du "Residual", og så ser du SS, altså RSS = 1149,00032
(Residual Sum of Squares)
-
Om jeg ikke tar helt feil, så tar du først dependent y med alle x'ene, og tar RSSu der ifra.
Etter på tar du dependent y og alle de x'ene som er igjen etter å ha satt B'ene som 0, altså
dependent y og independent x2 x3 og x4
Så tar du RSS'en fra dette datasettet, og får RSSr
m = 3, n = 30 og k = 7
Så kan du bruke :
((RSSr - RSSu) / m) / ((RSSu / (n - k )) = 1,42
Har ikke sjekket om svaret er rett enda, men virker logisk. -
Læreren våres sa han forventa minst 12 sider.. Som er 3-4 A4 ark?
-
-
Hvor er det man finner hvilke fag man kan velge?
Jeg fikk dette på mail av BI Stavanger, da jeg spurte.
-
Har noen fått mulighet til å velge valgfag? De skulle åpne for dette 10-20 juni trodde jeg?
Var hvertfall labert utvalg i Stavanger.. Tabbe og flytte fra Kristiansand der de skulle ha et nytt spennendes finansfag.
Edit: Det var visst 10-20 juli etter jeg leste mailen

Fagene på BI Stavanger
- ELE 3707 Sosiale medier
- ELE 3743 Personlig økonomi
- ELE 3704 Strafferett og økonomisk kriminalitet
- MRK 3400 Kulturforståelse
- MRK 3510 Markedskommunikasjon
- MRK 3544 Politisk økonomi
Noen som har hatt noen av de og vet om noe er kjekt for en finans og samfunnsøkonomi interessert student?
Metode og Økonometri (BI V2014)
i Skole og leksehjelp
Skrevet
Fordi det er ett valg i flervalgsoppgaven.. Se oppgave 21 på høst 2011.
Usikker på om du stiller spørsmål om avrundingsregler, så..
Og skal du fjerne en desimal fra 3,316, så vil det naturligvis være å opprunde 0,016 til 0,020, som gir 3,32.