

perrydinho
-
Innlegg
10 -
Ble med
-
Besøkte siden sist
Innholdstype
Profiler
Forum
Hendelser
Blogger
Om forumet
Innlegg skrevet av perrydinho
-
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
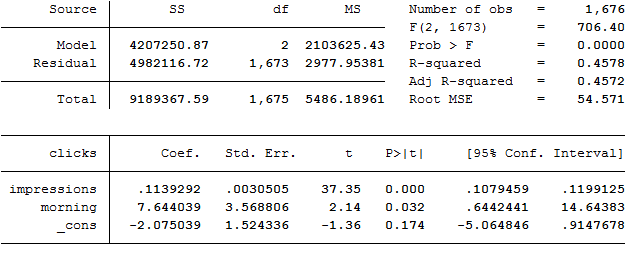
Hei, det eneste jeg gjorde på H var å bruke robust av oppgave E, men det er ikke nødvendig i det hele tatt. Man kan også se på modellen på oppgave E at det er kun impressions som er riktig. Det er tosidig test så da skal alle p verdier over 0,10 vekk?
Det er kun derfor den er ulik oppgave. Men startmodellen har jo ikke så mye å si. Det er resultatet av den modellen.
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Fordi jeg har samme som deg helt frem til H og lurer på om det er jeg som har gjort det rette eller om det er du. Man skal jo ta utgangspunkt fra oppgave E og da er det både impressions og morning som er signifikante på 10% signifikansnivå?
De med p>|t| over 0,10 skal ut, altså det er jo alle bortsett fra impressions.
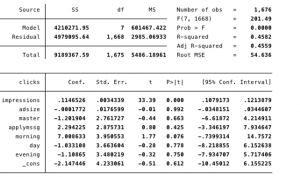
Ja, de over 0.10 skal ut, men morning har jo 0.032 altså under 0.1. Blir jo 3,2% ikke 32%, om du skjønner? Så den er jo signifikant? Har sjekket resten av alt vi har gjort, og vi har gjort alt likt, så tror vi har gjort ting riktig =) Meeeen jeg tror også at det er jeg som har rett på H...?
Ser jo her at Morning er på 0.076 som er <0.1 ?
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Hei, det eneste jeg gjorde på H var å bruke robust av oppgave E, men det er ikke nødvendig i det hele tatt. Man kan også se på modellen på oppgave E at det er kun impressions som er riktig. Det er tosidig test så da skal alle p verdier over 0,10 vekk?
Det er kun derfor den er ulik oppgave. Men startmodellen har jo ikke så mye å si. Det er resultatet av den modellen.
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Fordi jeg har samme som deg helt frem til H og lurer på om det er jeg som har gjort det rette eller om det er du. Man skal jo ta utgangspunkt fra oppgave E og da er det både impressions og morning som er signifikante på 10% signifikansnivå?
De med p>|t| over 0,10 skal ut, altså det er jo alle bortsett fra impressions.
Ja, de over 0.10 skal ut, men morning har jo 0.032 altså under 0.1. Blir jo 3,2% ikke 32%, om du skjønner? Så den er jo signifikant? Har sjekket resten av alt vi har gjort, og vi har gjort alt likt, så tror vi har gjort ting riktig =) Meeeen jeg tror også at det er jeg som har rett på H...?
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Fordi jeg har samme som deg helt frem til H og lurer på om det er jeg som har gjort det rette eller om det er du. Man skal jo ta utgangspunkt fra oppgave E og da er det både impressions og morning som er signifikante på 10% signifikansnivå?
det der er min oppg. H
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Fordi jeg har samme som deg helt frem til H og lurer på om det er jeg som har gjort det rette eller om det er du. Man skal jo ta utgangspunkt fra oppgave E og da er det både impressions og morning som er signifikante på 10% signifikansnivå?
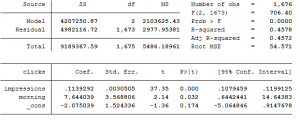
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
Fordi jeg har samme som deg helt frem til H og lurer på om det er jeg som har gjort det rette eller om det er du. Man skal jo ta utgangspunkt fra oppgave E og da er det både impressions og morning som er signifikante på 10% signifikansnivå?
-
Har løst oppgaven.
Lurer på om noen vil sammenligne
Hei, en av oss har rotet på oppgave H. Det blir oppgitt at man skal ta utgangspunkt i case oppgave E, så jeg lurer på hvorfor du har brukt den startmodellen du har brukt? Det er jo ikke samme modell som oppgave E?
-
Hei, jeg har løst alle oppgaver og er ute etter å sammenlikne med noen andre som også har gjort dette. Blir litt usikker når jeg ser at folk får litt diverse her.

Send PM om noen er interesserte.
-
Hei er det noen som har lyst til å dele fremgangsmåte på hvordan man gjør E,F,G,H? Har selv fått til A,B,C,D og deler gjerne om noen lurer på noe. Noen som har tips om hvor man kan lese og lære om hvordan man bruker Stata ordentlig? Foreleser har nevnt at vi skal titte på dataoppgaver + videoer forbundet med kapitler i metriboka, hvor finner jeg dette?
-
Folk er så krise as. Hva er det med dere og klage for alt? Er det så veldig interessant å høre på folk banne på opplastede videoer? Bann så mye du vil når du gamer eller gjør andre ting, men du trenger ikke laste opp videoer som er tilgjengelige for småbarn fulle av banneord.
-
 1
1
-
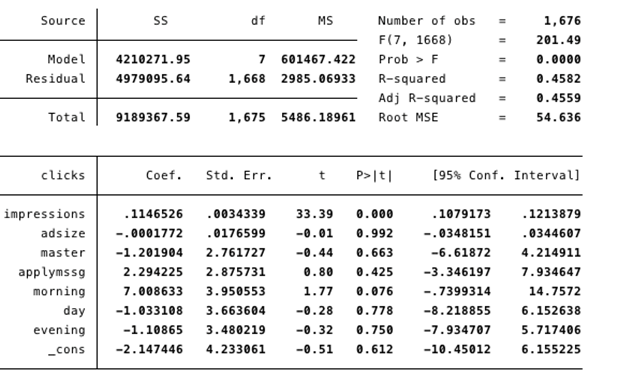
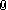
Metode & Økonometri BI V16
i Skole og leksehjelp
Skrevet
Clicks, impressions, uniqueimp & adsize = Forholdstallnivå
Master, applymssg & timeofday = Nominalnivå
:-)