

Axxxy
-
Innlegg
507 -
Ble med
-
Besøkte siden sist
Innholdstype
Profiler
Forum
Hendelser
Blogger
Om forumet
Innlegg skrevet av Axxxy
-
-
Her må du bruke noe som heter "regex". -> https://www.regexbuddy.com/regex.html
Det er tildels komplisert.
"fisk(.+?)mus"
Denne vil hente ut alt mellom fisk og mus.
Denne er fin -> https://www.johndcook.com/blog/powershell_perl_regex/
$text = "fskiiskffiskumhmmusssusm" $matches = [regex]::matches($text, "fisk(.+?)mus") $output = $matches.groups[1].value
-
Takk for det, selv om koden din ser fint og flott ut tror jeg jeg tar å prøver på å kode ut-hentingen av data selv

kopierte dog denne:
$doc.LoadHtml((iwr $url).RawContent)
(Du vet forresten ikke hva iwr som står fremfor $url i ovennevnte kodelinje betyr?Nei det gjør jeg ikke haha, så lenge det funker er jeg fornøyd. Kan alltids google det.
"//*[@id=forecastTable]/table/tbody/tr[3]/td[2]"Noen ganger har jeg opplevd at en tbody sniker seg inn selv om den ikke vises i kilde koden på chrome. Det ser du evt. når du analyserer html koden HAP har fått tak i.
`n = Ny linje `t = Tab
`n er det samme som ny linje når du trykker på ENTER i et word dokument.
`t gir samme effekt som når du trykker på TAB (knappen over caps lock). Den flytter teksten fremover med 4 mellomroms mellomrom ish.
-
Neste utfordring: Hvordan hente dette direkte fra web uten å mellomlagre lokale .html filer
Jeg har skrevet et fullverdi script i PowerShell som fungerer. I tilfelle du ønsker å finne ut av det selv, skjuler jeg koden i en spoiler.
Jeg har lagt inn kommentarer for alle kommandoene som beskriver hva de gjør.
Scriptet henter ut HTML koden fra pollenvarslingen.no og mater den direkte til HAP før den bruker xPath til å finne utvalgte elementer.
# CD to specified folder. # Importing HAP add-type -Path .\HtmlAgilityPack.dll # URL $url = "http://www.pollenvarslingen.no/Forsiden/Varsel.aspx" # Creating HAP document $doc = New-Object HtmlAgilityPack.HtmlDocument # Read and parse HTML content $doc.LoadHtml((iwr $url).RawContent) # Get the element concerning specified area $tr = $doc.DocumentNode.SelectSingleNode(".//tr/td[@class='fcRegion']/a[contains(text(), 'Sentrale')]/../..") # Ignoring the first td, getting the second td element. #$td = $tr.SelectSingleNode(".//td[2]") # Echo the value in the "title" attribute #echo $td.Attributes["title"].value #------------------------------------------------------ # Echoing all the values in a nicely formated way #------------------------------------------------------ # Echoing the name of the area Write-Host $tr.SelectSingleNode(".//td[1]").InnerText `n # Echoing all the "title" attributes Write-Host Or - Idag:`t`t`t $tr.SelectSingleNode(".//td[2]").Attributes["title"].value Write-Host Or - Imorgen:`t`t $tr.SelectSingleNode(".//td[3]").Attributes["title"].value Write-Host Hassel - Idag:`t`t $tr.SelectSingleNode(".//td[4]").Attributes["title"].value Write-Host Hassel - Imorgen:`t $tr.SelectSingleNode(".//td[5]").Attributes["title"].value Write-Host Salix - Idag:`t`t $tr.SelectSingleNode(".//td[6]").Attributes["title"].value Write-Host Salix - Imorgen:`t $tr.SelectSingleNode(".//td[7]").Attributes["title"].value Write-Host Bjork - Idag:`t`t $tr.SelectSingleNode(".//td[8]").Attributes["title"].value Write-Host Bjork - Imorgen:`t $tr.SelectSingleNode(".//td[9]").Attributes["title"].value Write-Host Gress - Idag:`t`t $tr.SelectSingleNode(".//td[10]").Attributes["title"].value Write-Host Gress - Imorgen:`t $tr.SelectSingleNode(".//td[11]").Attributes["title"].value Write-Host Burot - Idag:`t`t $tr.SelectSingleNode(".//td[12]").Attributes["title"].value Write-Host Burot - Imorgen:`t $tr.SelectSingleNode(".//td[13]").Attributes["title"].valueOm du ønsker å få varsler fra et annet sted, legg inn din egen xPath, eller bytt ut "Sentrale" med f.eks "Romsdal" på slutten av xPath kommandoen.
Just in case:
`n = Ny linje `t = Tab
-
Flotte greier!
Her har du 2 linker som beskriver hvordan du kan hente ut HTML koden fra nettsider direkte.
https://superwidgets.wordpress.com/tag/read-html-via-powershell-powershell/
http://dotnethappens.com/powershell-screen-scraping-using-xpath-selectors-and-htmlagilitypack/
En annen ting å ha i baktankene er at når du bruker tr[3], så henter den ut det 3. tr elementet. Om nettsiden du henter ut data fra en dag skulle bestemme seg for å legge inn et ekstra tr element i starten av dokumentet, så vil du endte opp med feil tr element, da elementet du er ute etter nå har flyttet seg til tr[4].
Nørd-info:
Om du kun skal hentet ut et element vil det egne seg bedre om du bruker "selectSingleNode".
1) Du unngår å få flere elementer med samme path.(den velger den første den møter på, det kan du forandre ved bruk av[])
2) den er kjappere da den slutter å lete i dokumentet når den har funnet en match.
-
Åjada, det er fortsatt mange millioner av xp maskiner som kjører den dag idag.
Det kan også være at vedkommende ikke vil bruke en annen versjon av Windows eller bruke penger på det.
-
CPU er vel den komponenten som er safest å kjøpe brukt. Meget sjelden at feil oppstår med cpu, ikke har den pinner heller som kan bli bøyd. Så synes halv pris ikke er feil i det hele tatt.
Haha oida, der sto det vist 600kr, la til en ekstra null jeg.. Mye mer realistisk det, skader ikke å prøve.
-
Har du lagg med å skive høres det ut som du er offer for keylogging o.l.
Det kan like greit komme av at PCen jobber som en jævel av ukjent grunn.
Regner med du har prøvd å sjekke oppgavebehandlingen når systemet går i stå?
-
Kanskje det er mulig å få solgt den cpu-en du har i dag for en 5-600 eller noe sånt.
What? Den CPUen selges for 1200kr idag, for ikke å tenke på at den er brukt.
-
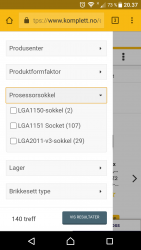
Selv om det vil koste deg, så vil jeg mye heller anbefale at du oppgradere både hovedkort og ram da alle 3 går hånd i hånd.
Socket 1150 er på vei ut, det samme gjelder ram ddr3. Du vil ende opp med mindre og mindre utvalg av deler da systemet ditt ligger en generasjon bak.
Selv om det koster, sparer du litt lenger og kjøper det et hovedkort med f. Eks socket 1151 og ram DDR4, sammen med en Intel som bruker socket 1151,så vil du ha et system som både er mye bedre, men samtidig lettere å oppgradere i senere tid.
Da unngår du å bruke penger på produkter nå som må byttes ut uansett om du en dag ønsker et bedre hovedkort/ram.
Men selvfølgelig, valget er opp til deg.
EDIT:
Her kan du se for deg selv. (vedlagt bilde)
-
 1
1
-
-
Neida, du skal fint kunne bruke korte uten problemer, men du vil ikke kunne bruke mer enn 128GB av kortet.
-
Men er ikke det litt av poenget med et lite samfunn? At ingen skal lede, alle står sammen.
Enste måten å løse det på er å gi opp livet og sitte der 20/7, eller få alle i gruppen til å jobbe sammen.
-
Bruker du Chrome... press F3
EDIT:
Jeg så i ettertid at du skrev "automatisk" så da vil ikke F3 funke.
Men du kan trykke F3 for så og søke etter ord på siden manuelt.
Da må du også i praksis scrolle helt ned til bunn av siden for å laste alle innlegg og kommentarer på siden, eller så vil du kun søke på de øverste innleggene.
-
Prøv å vær helt sikker før du evt. Bestiller nye for en tusenlapp, sure penger om feilen ligger et annet sted.

-
Tenkte mer på den.
Bare at NRK kan vel ikke svare på det heller, med mindre det er snakk om salg av TVer til folk som ikke har betalt lisens før.
Ikke helt det jeg leter etter det heller...
Jo stemmer det, tenkte helt feil

-
Og hvor mange TVer blir det solgt årlig i Norge? Hvor ofte bytter vi gjennomsnittlig TVer?
Tenkte mer på den.
-
Kontakt NRK, om det er noen som vet hvem som her TV, så er det dem..
-
HAP og alle andre xml/HTML parsere tar ren tekst som input og kommer ut med et objekt. Hvordan og hva dette objektet er varierer ut ifra hvilken modul du bruker, men det går relativt ut på det samme. Og det er akkurat det som gjør det mulig å navigere i xml/HTML dokumentet. XPath funker derfor bare med et slikt dokument, da den ikke behandler det som ren tekst men et "tree" system, litt på samme måte som du organiserer mapper på datamaskinen.
Invoker-WebRequest brukes til å hente data fra nettet i.e HTML koden i en nettside. Du bruker da invoker til å hente koden også kan du sende den direkte til HAP, isteden for å lagre den lokalt i en fil før du åpner den selvfølgelig. Hvilken kommando du må bruke for å gi HAP ren tekst isteden for et fil er jeg usikker på, men det finner du nok ut av
Desidert! Selv om de bygger på mye av det samme så inneholder HTML så mye annet. Jeg vil anbefale deg på det sterkeste å øve deg på et xml dokument sammen med HAP. Ta en rss feed fra VG.no for eksempel.
-> http://www.vg.no/rss/feed/?categories=1068&keywords=&limit=10&format=rss
Her vil du finne de 10 siste artiklene til VG som blir konstant oppdatert. Hver artikkel ligger i "item" tags, der finner du tittelen, linken, description, dato osv osv. Alle item tags ligger i "channel" taggen.
Det som kan være greit å legge merke til er at det første elementet i xml filen er en "rss" tag, og det første elementet referer man ikke til, det er elementet du sitter med som standard når du HAP har lest xml/HTML teksten.
For å hente ut tittelen til en/eller flere artikler, ville du brukt følgende XPath:
"/channel/item/title"
Nå som du har det ene eller alle tittel elemente(ne) (kommer helt an på om du bruker SelectNodes eller SelectSingleNode), da kan du hente ut teksten med "InnterHtml".
Prøv å lag et enkelt program der du går gjennom hver enkel "item" tag og echo'er ut tittel+link, I.e:Tittel Link Tittel Link ..
Om xml/HTML dokumentet du går gjennom har flere tags med samme navn som leder forskjellige steder, da kan du spesifisere taggen du vil ha med "attribute" verdiene:
<div class="number1"> <div class="number2"> <div>
Bruker du XPath ("/div") ovenfor, da ender du opp med alle 3. For å spesifisere hvilken "class" verdi du er ute etter, gjør følgende.
"div[@class='number2']"
Denne XPath koden vil kun gi deg det midterste elementet.
Det er også veldig viktig å vite forskjell på når XPath kommandoen starter med
(/) - absolute path - begynnelsen av dokumentet.
(//) - vet du ikke hvor dypt taggen(e) ligger? Bruk denne.
(.//) - har du fått tak i et element fra dokumentet og du ønsker å søke fra begynnelsen av elementet du har, og ikke fra begynnelsen av dokumentet, bruk denne.
Håper dette er med på å dytte deg i rett retning. Får du problemer underveis, da må du bare spørre om hjelp
Bruker mobil og har ikke tilgang til disse fancye innstillingene, så jeg skal formatere innlegget i morgen. -
Blir mangen poster her nå, men man oppdager stadig noe nytt i denne data verdnene

- Her har du et greit start punkt når det kommer til xpath -> https://www.w3schools.com/xml/xpath_intro.asp
- Siden xpath tydligvis er universalt uansett hvilket språk du jobber med, ikke tenk på å google etter powershell spesifikke spørsmål når du bruker xpath.
- Bli kjent med kommandoene og funksjonene du kan bruke på et HAP dokument, som å hente ut teksten fra et element "InnerHtml". Xpath brukes i hovedsak til å hente elementet du er ute etter, derfra kan du prosessere resultatet med innebygde kommandoer og funksjoner.
Om du ønsker å få deg et bedre overblikk med HTML koden du jobber med og ikke allerede har gjort det:
- Last ned og installer gjerne Notepad++, det er en text editor som støtter omtrent alle språk. Lim inn f.eks HTML koden du jobber med, trykk på "languages" i menyen på toppen og velg HTML. -> https://notepad-plus-plus.org/download/v7.3.2.html
- Er HTML koden du jobber med bulkete og rotete? Formater den med mellomrom, bare husk å velge enten 2 eller 4 spaces da de fleste text editors jobber med dem. -> http://www.freeformatter.com/html-formatter.html
Bruker nevnt verktøy ovenfor konstant. Det er mye lettere å forstå hva som ligger hvor.
-
Update.
# For å få tak i teksten til elementet som ligger i $texts $texts.InnerText # For å få tak i HTML koden til elementet som ligger i $texts $texts.OuterHtml # For å få en liste med kommander du kan bruke sammen med $texts $texts | Get-Member # Herfra kan du repetere samme SelectNodes(for alle) eller #SelectSingleNode(for den første den møter på) $texts objektet. $texts.SelectSingleNode("td[@class='fcValueCellRight']") # Koden ovenfor vil velge TD elementet der class='fcValueCellRight', #altså den siste TD taggen som ligger TR elementet du jobber med.Bare husk at du jobber nå med objekter og ikke tekst.
-
Jada, fikk det til!
I tilfelle du ikke allerede har gjort det:
1) Last ned HtmlAgilityPack herfra -> https://htmlagilitypack.codeplex.com/
2) Pakk ut en av mappene hvor enn du vil, jeg brukte "Net45" filene.Og her finner du dokumentasjonen på HAP -> https://htmlagilitypack.codeplex.com/downloads/get/120935#
Den ligger i en .chm fil du må laste ned og åpne.
Ved å bruke eksempelet som ligger på bunn her -> http://www.leeholmes.com/blog/2010/03/05/html-agility-pack-rocks-your-screen-scraping-world/
add-type -Path .\HtmlAgilityPack.dll $doc = New-Object HtmlAgilityPack.HtmlDocument # Om du har HTML dokumentet lagret i en fil, bruk: $result = $doc.Load("path\to\your\file\texts.html") # Her kan du bruke xpath. # SelectNodes velger 'alle' nodene den møter på som stemmer med søket. $fjellstrok = $doc.DocumentNode.SelectNode(".//tr/td[@class='fcRegion']/a[contains(text(), 'Sentrale')]/../..") # Skriv inn $fjellstrok og du får en vegg av en tekst som inneholder kun de elementene du er ute etter.Referer til brukermanualen eller google for å lære mer om HAP.
-
Om du tilfeldigvis har noen erfaring med dette i powershell hadde det vært fint

Det har jeg dessverre ikke, men ut ifra det jeg har sett idag så kjenner jeg at jeg må lese litt på hva powershell kan.
Tar en kikk på dette her nå, ser om jeg får til noe interessant i forhold til det du er ute etter.
-
Men som sagt har jeg ikke krysset av for hverken Full control eller Modify. Så ut i fra den listen skulle dette virket som jeg vil. Men det gjør det ikke.
Med "krysset ut" trodde jeg du mente at du hadde blokkert følgende.
Da virker det jo riktig. Hadde samme problemet langt tilbake i tid, da virket det som om den lagret instillingene, men det gjorde den ikke. Hva løsningen på mitt problem var har gått i glemmeboken.
Hva skjer om du huker av "Read & Execute"?
-

"Full control" overskriver alle instillingene du induviduelt takket nei til
source -> https://msdn.microsoft.com/en-us/library/bb727008.aspx
Edit: Scroll ned på siden og les på "Special Permissions", der finner du det du trenger.
-
kom ny driver til nvidia i dag.
Konge, laster ned nå, håper det løser mine bugs
POWERSHELL: Sliter med å filtrere innhold i string fra HTML
i Programmering og webutvikling
Skrevet · Endret av Axxxy
Gratulerer!
Ja, du var ganske uheldig med hvor knotete HTML koden var laget. Som regel pleier det å være lettere å finne frem, men siden TR elementet i seg selv ikke hadde så mye å by på for å identifisere seg selv (alle TR elementene hadde class=fcRegion).
Utenom det så ser koden din veldig fin ut! Det er også bra at du ikke har satt inn mellomrom i koden som har med output å gjøre for at det skal se beint ut (slik jeg gjorde i mitt tidligere eksempel), det er sett på som "bad programming practice".
Om det er en ting jeg skal pirke på, så hadde jeg byttet ut;
.outerHTML.split('"')[1]med
Utenom det, tommel opp!
Neste blir vel å lage en app som rister i lomma når det er fare for spredning?